Invisible Stitch: Generating Smooth 3D Scenes with Depth Inpainting
Visual Geometry Group, University of Oxford
Building 3D Scenes With Depth Inpainting
To hallucinate scenes beyond known regions and lift images generated by 2D-based models into three dimensions, current 3D scene generation methods rely on monocular depth estimation networks. For this task, it is crucial to seamlessly integrate the newly hallucinated regions into the existing scene representation. Simple global scale-and-shift operations to the predicted depth map, as used by previous methods, might lead to discontinuities between the scene and its hallucinated extension. We introduce a depth completion network that is able to smoothly extrapolate the existing scene depth based on an input image.
View a larger version of this figure
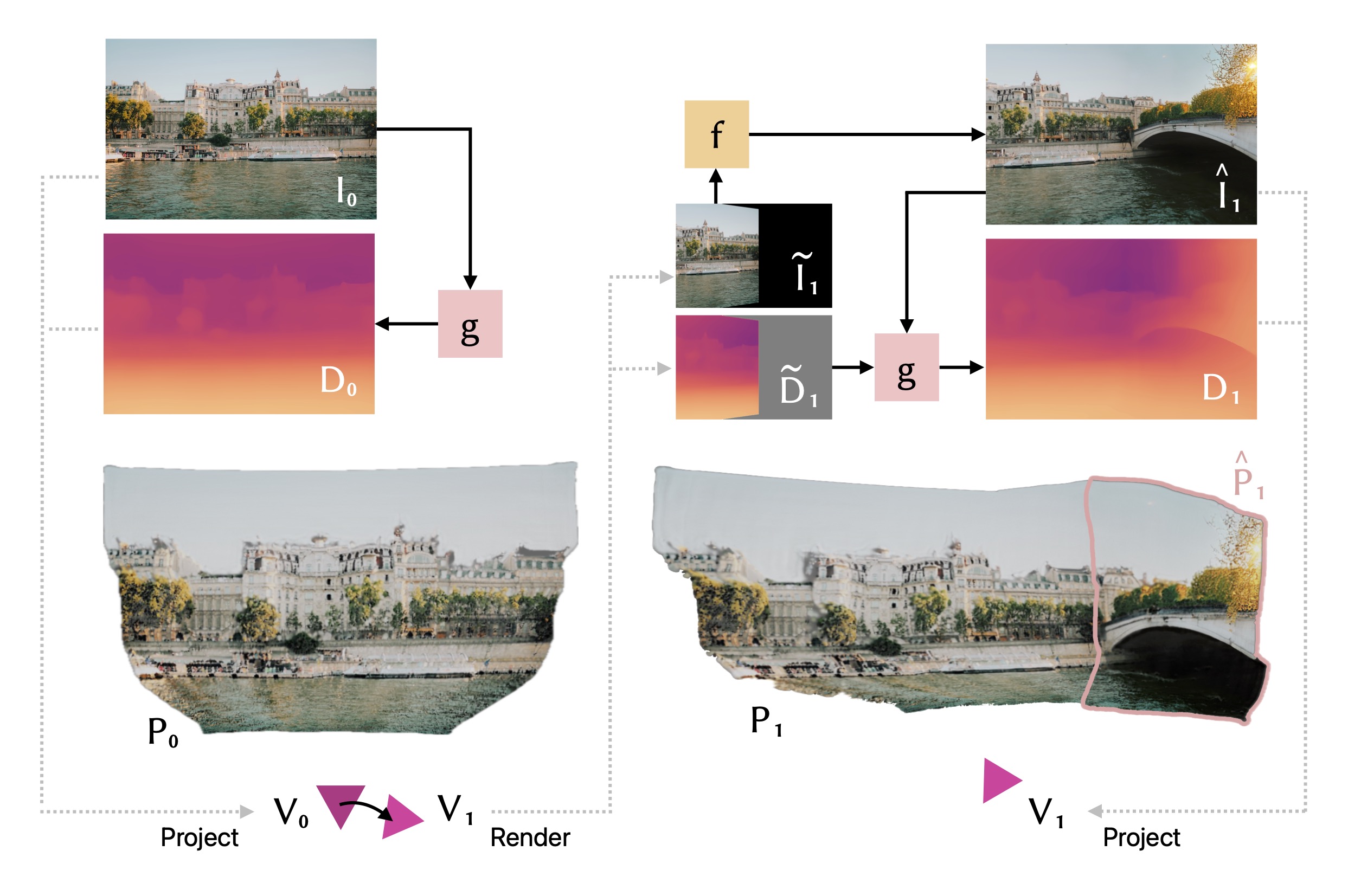
Overview of our 3D scene generation method. Starting from an input image , we project it to a point cloud based on a depth map predicted by a depth estimation network . To extend the scene, we render it from a new view point and query a generative model to hallucinate beyond the scene's boundary. Now, we condition on the depth of the existing scene and the image of the scene extended by to produce a geometrically consistent depth map to project the hallucinated points. This process may be repeated until a 360-degree scene has been generated.
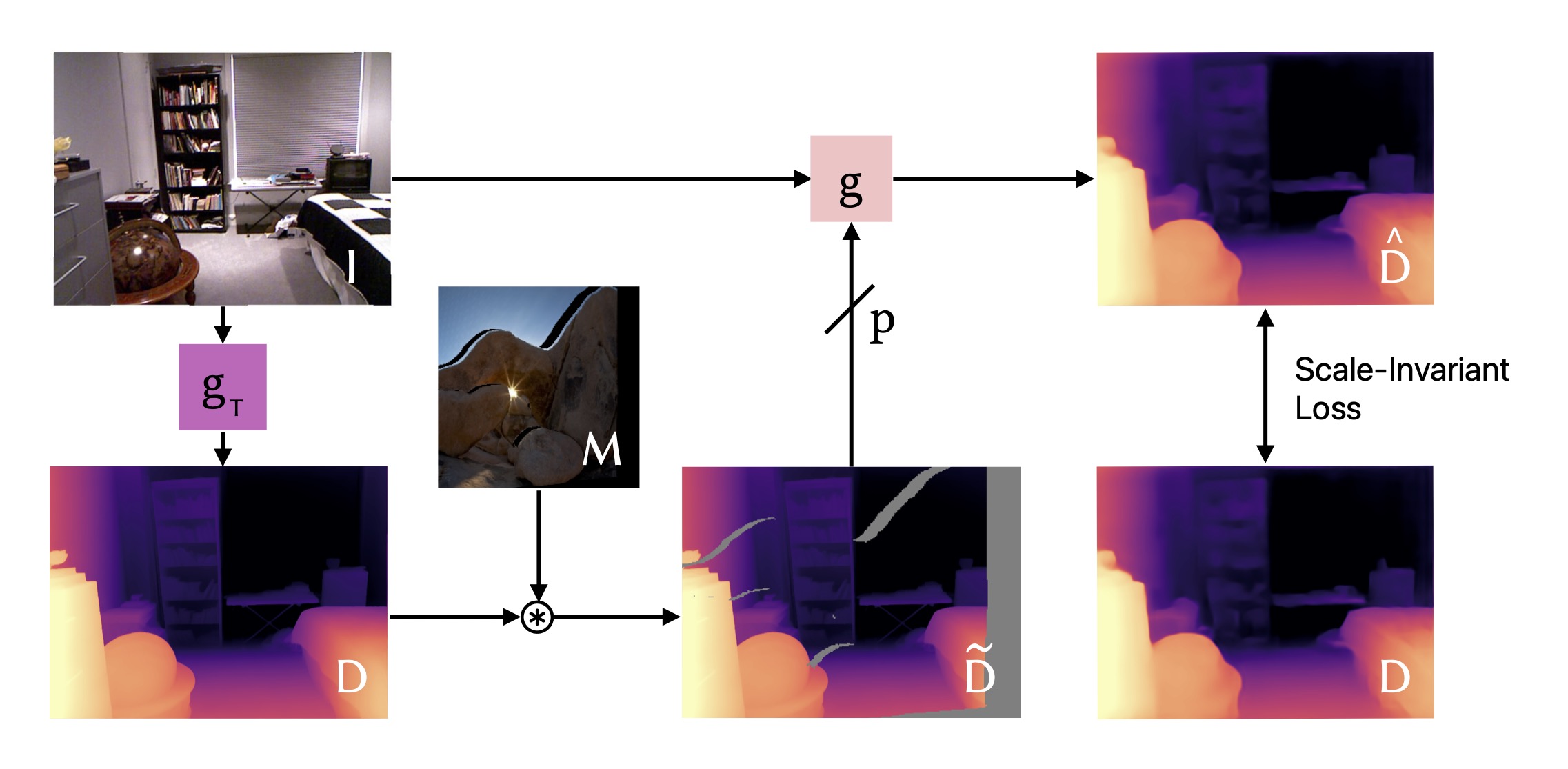
The depth completion network learns to inpaint masked depth map regions by being conditioned on an image and the depth of known regions. We use masks that represent typical occlusion patterns generated by view point changes. To retain the model's ability to predict depth if no sparse depth is available, the sparse depth input is occasionally dropped.
View a larger version of this figure
Overview of our training procedure. In this compact training scheme, a depth completion network is learned by jointly training depth inpainting as well as depth prediction without a sparse depth input (the ratio being determined by the task probability ).A teacher network is utilized to generate a pseudo ground-truth depth map for a given image . This depth map is then masked with a random mask , to obtain a sparse depth input .
360-Degree Scene Results
"a view of Zion National Park"
Evaluating Scene Geometry
Within the fully generative task of scene generation, evaluating the geometric properties of generated scenes is difficult due to the lack of ground-truth data. Most existing work resorts to image-text similarity scores, which only measures the global semantic alignment of the generation with a text description. To evaluate the geometric consistency and quality of the depth predictions used to build the scene, we propose a new evaluation benchmark. This benchmark quantifies the depth-reconstruction quality on a partial scene with known ground truth depth.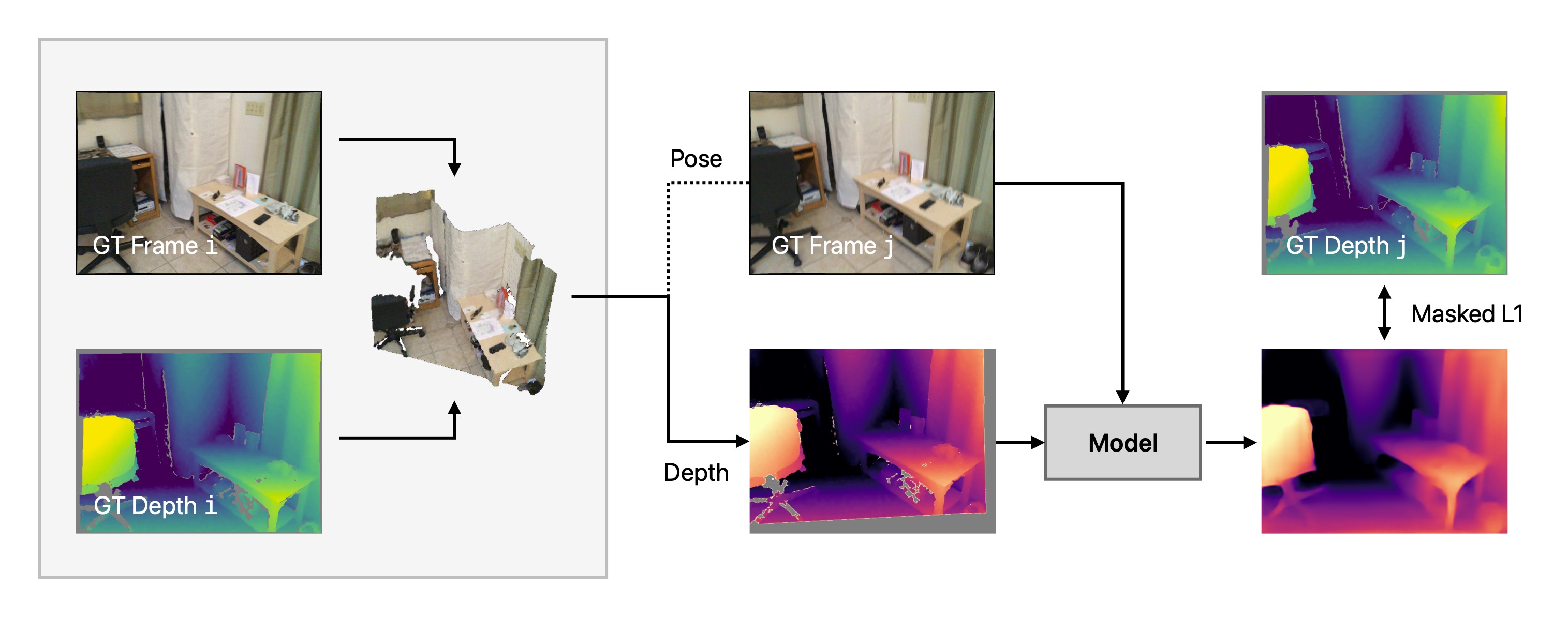
View a larger version of this figure
Overview of our scene consistency evaluation approach. Assume a scene is described by a set of views with associated images, depth maps, and camera poses, where the overlap of two views is described by a function . For a given view pair with , we generate a representation, e.g., a point cloud, from the ground-truth (GT) data for . Then, we render the representation from the view point of . We feed the corresponding ground-truth image and the representation's depth into the model under consideration to extrapolate the missing depth. Finally, we calculate the mean absolute error between the result and the ground-truth depth for , only considering those regions that were extrapolated.
In both, a real-world and a photorealistic setting, our inpainting model produces predictions that are more faithful to the ground-truth than prior methods.
Abstract
3D scene generation has quickly become a challenging new research direction, fueled by consistent improvements of 2D generative diffusion models. Most prior work in this area generates scenes by iteratively stitching newly generated frames with existing geometry. These works often depend on pre-trained monocular depth estimators to lift the generated images into 3D, fusing them with the existing scene representation. These approaches are then often evaluated via a text metric, measuring the similarity between the generated images and a given text prompt. In this work, we make two fundamental contributions to the field of 3D scene generation. First, we note that lifting images to 3D with a monocular depth estimation model is suboptimal as it ignores the geometry of the existing scene. We thus introduce a novel depth completion model, trained via teacher distillation and self-training to learn the 3D fusion process, resulting in improved geometric coherence of the scene. Second, we introduce a new benchmarking scheme for scene generation methods that is based on ground truth geometry, and thus measures the quality of the structure of the scene.
Acknowledgements
P. E., A. V., I. L., and C.R. are supported by ERC-UNION- CoG-101001212. P.E. is also supported by Meta Research. I.L. and C.R. also receive support from VisualAI EP/T028572/1.